The Index Is The ____________ Of A Piece Of Data.
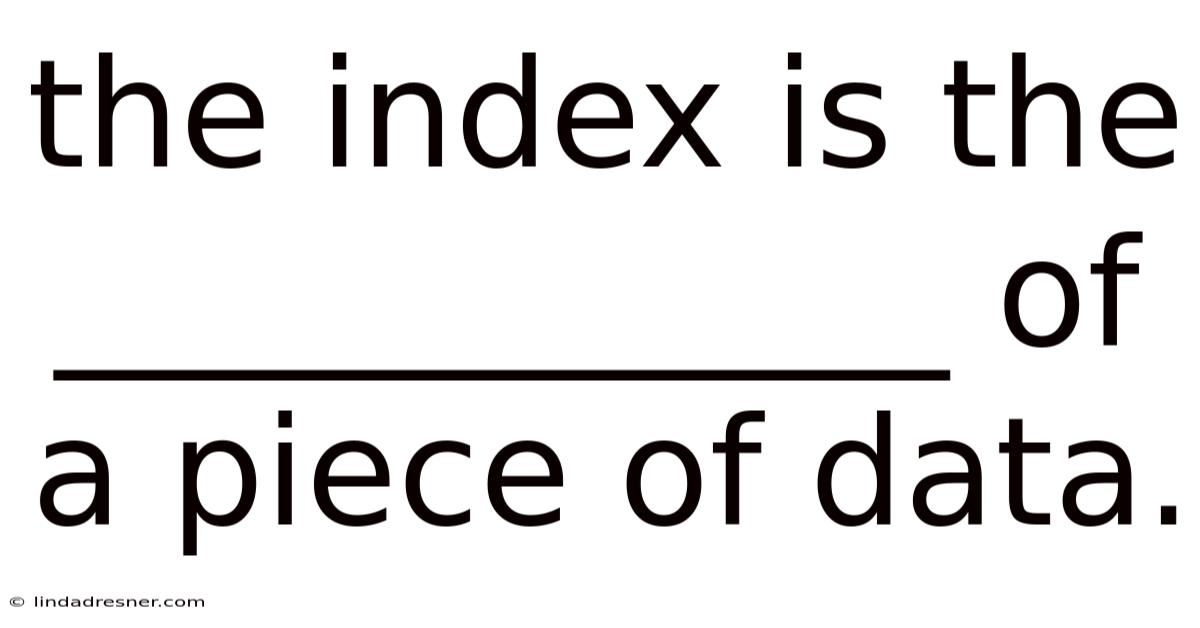
The Index Is the Position of a Piece of Data
In the realm of data management and computer science, the term index holds significant importance. At its core, the index is the position of a piece of data within a structured system. This concept is foundational to how data is organized, retrieved, and manipulated efficiently. Whether in databases, programming, or statistical analysis, an index serves as a reference point that allows for quick access to specific data elements. Understanding what an index is and how it functions can greatly enhance one’s ability to work with data effectively.
What Is an Index in Data?
An index, in the context of data, is a mechanism that maps data to its location or identifier. It acts as a pointer or a key that helps locate a specific piece of information without scanning through all the data. For instance, in a database, an index might be a table that contains a subset of the data’s columns, along with pointers to the actual data rows. This allows queries to find information much faster than searching through every record.
The idea of an index is not limited to databases. In programming, an index often refers to the numerical position of an element in an array or list. For example, in a list of names stored in an array, the first name might be at index 0, the second at index 1, and so on. This numerical labeling is crucial for accessing and modifying elements in a structured way. Similarly, in statistics, an index could represent a measure that summarizes a dataset, such as a Gini coefficient or a price index, which provides a snapshot of trends or distributions.
The Role of an Index in Data Management
The primary role of an index is to improve the efficiency of data retrieval. Without indexes, systems would have to perform a linear search, which can be time-consuming, especially with large datasets. By creating an index, the system can quickly narrow down the search space, reducing the time and computational resources required.
For example, consider a database containing millions of customer records. If a user wants to find all customers from a specific city, the database can use an index on the "city" field to locate the relevant records almost instantly. This is because the index stores the city names in a sorted or hashed format, allowing for rapid lookups. Without such an index, the database would have to scan through every record, which is inefficient and slow.
Indexes also play a critical role in ensuring data integrity. In some cases, indexes are used to enforce uniqueness, such as primary keys in databases. A primary key index guarantees that each record in a table has a unique identifier, preventing duplicate entries and maintaining data consistency.
Types of Indexes in Different Contexts
Indexes come in various forms depending on the context in which they are used. In databases, common types include:
- B-tree indexes: These are hierarchical structures that allow for efficient range queries and are widely used in relational databases.
- Hash indexes: These use a hash function to map data to specific locations, making them ideal for exact match queries.
- Clustered indexes: These determine the physical order of data in a table, optimizing access patterns.
- Non-clustered indexes: These are separate structures that store the index data and pointers to the actual data.
In programming, indexes are typically numerical and used to access elements in data structures like arrays, strings, or lists. For instance, in Python, a list’s elements are accessed using zero-based indexing, where the first element is at index 0.
In statistics, indexes might take the form of composite measures. For example, the Consumer Price Index (CPI) is a statistical index that tracks changes in the price level of a basket of consumer goods and services. Similarly, the Human Development Index (HDI) combines indicators like life expectancy, education, and income to provide a composite score of a country’s development.
How Indexes Improve Data Retrieval
The efficiency of data retrieval is one of the most significant advantages of using indexes. By creating an index on a specific field,
...the system can dramatically reduce the time it takes to locate and retrieve relevant data. This speed boost is particularly crucial in applications dealing with real-time data, such as search engines, e-commerce platforms, and financial trading systems. The impact of an index isn’t just about speed; it also directly correlates with the responsiveness and user experience of these applications.
Furthermore, indexes contribute to improved query performance by allowing the database or system to avoid scanning the entire dataset. Instead, it can pinpoint the exact location of the desired information, significantly reducing I/O operations – the process of reading data from storage devices. This reduction in I/O translates to lower energy consumption and reduced wear and tear on hardware, contributing to both cost savings and increased system longevity.
It’s important to note that while indexes enhance retrieval speed, they also introduce a small overhead during data modification operations like inserts, updates, and deletes. Each time data is changed, the index must also be updated to reflect the changes. Therefore, the strategic placement and maintenance of indexes are critical for optimal performance. Over-indexing can actually slow down write operations, while under-indexing can negate the benefits of faster reads.
The choice of which fields to index, and the type of index to use, should be based on a thorough understanding of the application’s query patterns. Analyzing frequently executed queries and identifying the fields used in WHERE clauses and JOIN conditions are key steps in designing an effective indexing strategy. Tools and techniques like query profiling can provide valuable insights into how data is being accessed, guiding the decision-making process.
Conclusion
Indexes represent a fundamental optimization technique across a remarkably diverse range of fields, from database management and programming to statistical analysis. Whether it’s accelerating database searches, streamlining array access in code, or providing a holistic measure of societal progress, the core principle remains the same: by creating a structured shortcut to relevant information, indexes dramatically improve efficiency and unlock the potential of data. Understanding the nuances of different index types and their impact on both read and write operations is paramount to harnessing their full power and ensuring optimal performance in any system that relies on data retrieval.
Ultimately, the effective use of indexes is a delicate balancing act. It requires a continuous evaluation of the system's workload and a willingness to adapt the indexing strategy as data volumes and query patterns evolve. Automated index management tools are becoming increasingly sophisticated, offering dynamic optimization and minimizing manual intervention. These tools can analyze query logs, identify unused or redundant indexes, and even suggest optimal indexing strategies based on real-time data access patterns.
Beyond the technical aspects, a strategic indexing approach is also a crucial element of data governance. It ensures data integrity and consistency by facilitating efficient data validation and error detection. A well-designed indexing system can significantly improve the reliability of data analytics and reporting, leading to more informed decision-making.
In the future, we can expect to see even more advanced indexing techniques emerge, leveraging technologies like machine learning and distributed computing to handle increasingly complex and voluminous datasets. Approximate indexing, for example, allows for faster retrieval speeds by sacrificing some degree of precision, a trade-off that is often acceptable in applications where near-instantaneous results are paramount. As data continues to grow exponentially, the importance of efficient indexing will only continue to increase, solidifying its position as a cornerstone of modern data management. The ability to quickly and reliably access information is no longer a luxury; it’s a necessity for innovation and progress across all sectors.
Latest Posts
Latest Posts
-
Checkpoint Exam Available And Reliable Networks Exam
Mar 19, 2026
-
What Escape Planning Factors Can Facilitate Or Hinder Your Escape
Mar 19, 2026
-
True Or False Individual Organisms Can Evolve Over Time
Mar 19, 2026
-
Thick Accumulations Of Dead Keratinocytes Are Called
Mar 19, 2026
-
Which Incident Type Requires Regional Or National Resources
Mar 19, 2026